本周主要学习了cuda编程,简单地了解了几种基于深度学习的人脸识别算法(DeepFace, DeepID, FaceNet, VGGFace)
1 CUDA编程
CPU+GPU的异构编程架构是高性能计算的主流,以高吞吐量与高效率完成复杂任务。其代码分为两部分,由主机端(CPU)运行代码与设备端(GPU)运行代码(核函数)组成。
CUDA编程中,内存管理,线程管理,设备管理是非常重要的概念,也是构成程序逻辑与影响程序效率的重要因素。除此之外CUDA编程需要了解GPU的架构,资源。CUDA程序流程大致分为以下几个部分:
- 主机端(CPU)内存分配,设备端(GPU)内存分配
- 把数据从CPU内存拷贝到GPU内存
- 调用核函数对存储在GPU内存的数据进行操作
- 将数据从GPU内存传回到CPU内存
1.1 内存管理
CUDA编程模型是由主机和设备组成,各自拥有独立的内存。为了使操作者拥有充分的控制权并使系统达到最佳性能,CUDA运行时负责分配与释放内存,并且在主机与设备内存之间传输数据。内存管理函数如下:

设备端的内存只有核函数能够读取,使用udaMemcpy()函数在主机与设备之间进行数据转移,如上面的4个步骤提到的,通常都是将主机端的数据拷贝到设备端,调用核函数对设备端的数据进行计算,再将计算之后的结果拷贝回主机端进行存储。
1.2 线程管理
线程管理是CUDA编程很重要的一个概念,从逻辑层的角度来看,GPU中各个线程并行进行(硬件层不一定都是并行)。CUDA的特点之一就是通过编程模型揭示了一个两层线程层次结构(grid+block),充分熟悉与理解线程层次结构对DUDA编程十分重要。
每启动一个核函数就会在设备中产生大量的线程,并且每个线程都执行由核函数指定的语句,产生的大量线程便是两层的线程结构进行管理,由线程块(block)与线程网格(grid)构成
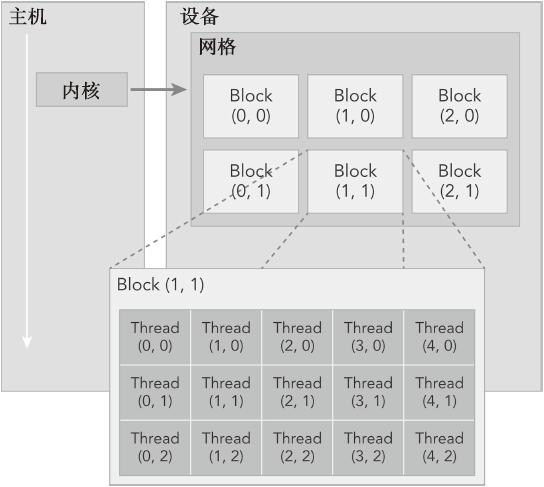
每启动一个核函数,就同时启动了一个网格(grid),网格最多可以为三维,维度值的最大值由硬件决定,我们服务器上的 GeForce GTX 1080 Ti 支持的最大网格维数为1D=(131072), 2D=(131072,65536), 3D=(16384,16384,16384) ,网格由块组成,这便是线程结构的第一层。块由线程组成,这便是第二层。他们的层次结构为: 网格(grid)–>块(block)–>线程(thread)
1.3 设备管理
前面说到了在逻辑层来说,各个线程都是并行运行的,但是在硬件层并不一定,并没有那么多的硬件资源供所有线程并行运行。设备管理需要清楚当前硬件的资源情况,对于程序的优化十分重要,设备管理需要对GPU的架构有一定了解,NVIDIA目前推出的最新架构为Turing,实验室服务器使用的 GeForce GTX 1080 Ti为Pascal架构,其资源如下图所示:
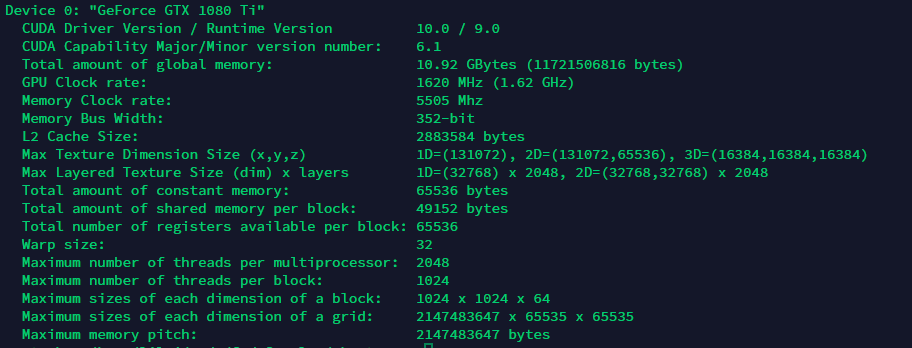
参数中
- Warp size: 32
- Maximum number of threads per multiprocessor: 2048
- Maximum number of threads per block: 1024
- Maximum sizes of each dimension of a block: 1024 x 1024 x 64
- Maximum sizes of each dimension of a grid: 2147483647 x 65535 x 65535
几个参数,对于编程时资源的分配十分重要
1.4 参考资料
- CUDA C编程权威指南(John Cheng)
2 基于深度学习的人脸识别算法
深度学习的人脸识别算法准确度大大地高于传统算法,准确度早已超过了人工识别准确率(DeepFace: 92.5%, DeepID: 99.15%, FaceNet-NN3: 99.65% , LFW数据集测试结果),所以现在深度学习在人脸识别方面的研究除了提高准确率之外还致力于裁剪网络结构,减小参数(VGGFace)
2.1 DeepFace
人脸识别可分为 detect-> align-> represent-> classify 几个部分,DeepFace在align部分使用了3D对齐技术,将检测到的人脸进行3D-aligned处理之后再放入网络中进行识别。网络结构如下图所示

从图中可以看出,检测到的是侧脸,经过3D-aligned处理之后面部调整为正面,讲调整后的图像输入网络。网络C1, C3表示卷积层,M2为max pooling层,L4, L5, L6为局部卷积层,F7, F8为全连接层。
2.2 DeepID
DeepID是在GoogleNet和VGGNet上的基础上进行改进,使之适应于人脸识别,网络有一代和二代两种,两种网络的区别主要在于损失函数的定义。常用的为DeepID2的损失函数,除了采用softmax训练构建分类器时产生的交叉熵函数之外,还添加了关于两张图片是不是一个人的损失函数,两个损失函数按权重组合,最终生成了对应的总损失函数用来进行训练,网络结构如下:
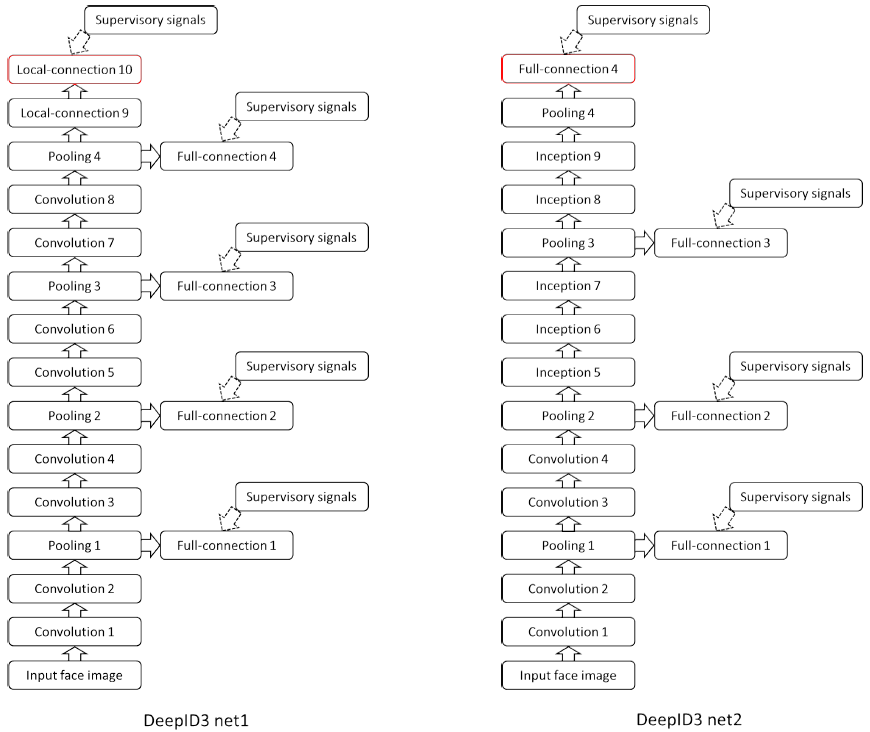
相比DeepFace,DeepID3的网络结构更深,且没有使用3D对齐技术,直接输入检测到的人脸图像进行识别。
2.3 FaceNet
FaceNetFaceNet是谷歌提出的网络结构, 网络在使用的过程中通过三元对来构造损失函数,直接根据学习到的特征向量,计算在一类的图片距离和不在一类的图片距离,训练的结果是一类之间的距离尽量小,不一类之间的距离尽量大。
2.4 VGGFace
VGGFace的网络在LFW数据集上的准确率为98.95%,虽然不及FaceID和FaceNet,但是网络结构更加简单,有更强的鲁棒性
2.5 参考资料
- DeepFace: Closing the Gap to Human-Level Performance in Face Verification [Yaniv Taigman et al., 2014]
- DeepID3: Face Recognition with Very Deep Neural Networks [Yi Sun et al., 2015]
- FaceNet: A Unified Embedding for Face Recognition and Clustering [Florian Schroff et al., 2015]
- Deep Face Recognition [Omkar M. Parkhi et al., 2015]