开学以来主要学习了CUDA优化相关的内容,创建了VS2015的cuda工程熟悉其编程与调试过程。人脸识别方面,调研了目前开源的人脸识别数据集,阅读了VGGFace与VGGFace2两篇论文,下载了Visual Geometry Group在2018年公布的VGGFace2 数据集并跑了一些主流的人脸识别模型。
1 CUDA 程序的优化
CUDA编程中,优化是非常关键的一步,算法的好坏极大地影响到程序的运行效率,优化的关键主要在于其执行模型与内存模型。执行模型中,线程束的调度,SIMD(单指令多数据)的理解,线程块大小个数的分配标准。内存模型中,全局内存,共享内存,缓存,常量内存的区别与使用方法以及各种内存与线程之间的关系。
1.1 执行模型
弄懂执行模型就是要知道成千上万的线程是如何在GPU中调度的,从硬件层面探讨内核的执行问题,首先要了解以下GPU硬件中的概念:
- cuda核
- 线程束(warp)
- SIMD(single instruction multi data)
- SM(stream multi processer)
1.1.1 cuda核
cuda核是为了适应GPU的大规模运算专门精简设计的算术逻辑单元(ALU),我们程序设计的线程便是在cuda核中计算处理。
1.1.2 线程束(warp)
线程束是一个重要的概念,每个线程束包含32个线程,32是cuda编程的一个重要数字。线程的执行都是按照线程束调度的而不是单个线程调度。
1.1.3 单指令多数据(SIMD)
前面讲到线程束之所以重要,就是(SIMD)架构决定的。顾名思义,单指令多数据,就是多个(32个)数据同时执行一个指令。也就是一个线程束(warp)中的32个线程同时执行一条指令(或者某些线程等待不执行任何操作,这样会浪费资源,需要优化),这也是考虑到并行处理时大量的重复指令设计的。
1.1.4 流式多处理器(SM)
流式多处理器(SM)是GPU架构的核心,一个SM由大量的cuda核,特殊功能单元,加载/存储单元组成。一个SM可以管理上千个线程束(不同型号GPU不同),SM个数便是常说的GPU核心数。
1.1.5 相互关系
以上几个概念的关系可以简单描述为:32个cuda核组成一个线程束,同一个线程束(32个cuda核)执行相同的指令即为SIMD(一个warp中的32个线程执行相同的指令),多个(不同型号GPU数目不同)warp组成一个SM,一块GPU包含多个SM (SM的个数便是常说的GPU核心数)。下图较好得描述了逻辑视图和硬件视图:
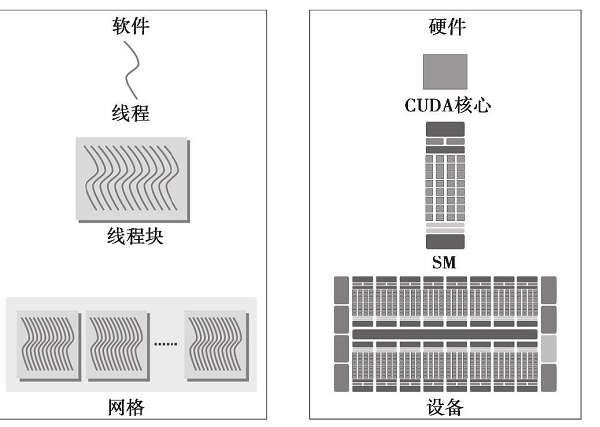
在了解了gpu的执行模型之后,将编程模型与执行模型结合,便能很好得理解block,grid的设计原则,以及block中线程的数量与性能之间的关系,是算法优化的一大因素。
1.2 内存模型
GPU中的内存主要分为两个部分,全局内存与共享内存,全局内存通过PCIE总线与CPU相连,可以直接通过CPU操作,即我们通常说的显存,容量大,速度相对较慢。共享内存只能在GPU内分配使用,即二级缓存,容量有限,速度快。共享内存是珍贵的资源,共享内存与全局内存的不同使用方法都会极大得影响到程序的性能,对于读写频繁的数据,转移到共享内存再操作会极大地提高运行速度。
1.2.1 常用内存
下面是常用内存地存取速度:
- Register – dedicated HW – single cycle
- Shared Memory – dedicated HW – single cycle
- Local Memory – DRAM, no cache – slow
- Global Memory – DRAM, no cache – slow
- Constant Memory – DRAM, cached – depending on cache locality
- Texture Memory – DRAM, cached – depending on cache locality
- Instruction Memory ( invisible ) – DRAM
实用关键字 __shared__在共享内存中创建变量,关键字__device__在全局内存中创建变量,以下是常用的变量声明方式
| 变量声明 | 存储器 | 作用域 | 生命期 |
|---|---|---|---|
| 单独声明的自动变量(非数组) | register | thread | kernel |
| 自动变量数组 | local | thread | kernel |
__shared__ int sharedVar |
shared | block | kernel |
__device__ int sharedVar |
global | grid | application |
__constant__ int sharedVar |
constant | grid | application |
1.2.2 内存与线程的关系
每个线程私有的为 Local Memory,local memory存储于全局内存中。共享内存(shared memory)为每个block共享,不同block之间不能相互访问。全局内存为整个设备共有。
1.3 参考资料
- CUDA C权威编程指南
- NVIDIA Fellow 周斌博士视频讲解
2 人脸识别
本次仅仅是训练的人脸识别,不包括人脸检测,使用的数据集也都是经过人脸检测切割之后的人脸图像。
2.1 人脸识别数据集介绍
深度学习在人脸识别领域取得了巨大的成功,但在2015年之前,都没有一个适用于深度学习的人脸识别开源数据集,比较大的超过百万张图片的数据集例如Google,Facebook的数据库都是公司私有并不公开。传统的人脸识别数据库如 LFW(Labelled Faces in the Wild),数据量都很有限。由于制作数据集成本高昂,所以人脸识别在学术届的发展较为缓慢,直到2015年牛津大学Visual Geometry Group实验室公布了VGGFace人脸识别数据集才得已改善,我们使用的是Visual Geometry Group实验室在2018年发布的VGGFace2数据集进行训练,下面是一些人脸识别数据集的介绍。

2.2 参考资料
- ZQ. Cao, L. Shen, W. Xie, O. M. Parkhi, A. Zisserman, VGGFace2: A dataset for recognising faces across pose and age, 2018. site, arXiv
- Parkhi, O. M. and Vedaldi, A. and Zisserman, A., Deep Face Recognition, British Machine Vision Conference, 2015.site
- K. Zhang and Z. Zhang and Z. Li and Y. Qiao, Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks, IEEE Signal Processing Letters, 2016. arXiv