本周测试了OpenCV使用GPU对视频的读写显示情况,结果显示仅使用OpenCV不能很好地完成视频编码工作,综合考虑可以使用 OpenCV + FFmpeg 的方法各自完成其擅长的工作。搭建了ffmpeg + opencv 的开发环境学习了ffmpeg 最新的编解码相关API。
1 OpenCV的硬编解码测试
OpenCV 的软编解码是在在ffmpeg 的基础上实现的,能够支持几乎所有视频的解码,H264 及之前的编码。OpenCV 硬编解码则是跳过ffmpeg 直接在NVIDIA 官方的编解码包Video Codec SDK 上实现的,所以硬编解码方面仅支持NVIDIA的显卡。
之前提到,opencv在视频编解码方面支持得不是很好,在硬编解码方面则更加脆弱,对底层环境得版本及其依赖,以下是试验得过程记录。
1.1 使用OpenGL进行显示
在代码调试过程中为了实时显示视频,查看编解码效果,使用OpenGL 进行加速显示,opencv 中使用OpenGL需要单独编译。要使opencv支持OpenGL,首先得安装QT 环境,使用QT中的OpenGL模块,并在使用CMake-GUI 时勾选 with_opengl = ON with_qt = ON。
但是QT官方提供的windows安装包只有32位的,并没有64位的。而若要编译支持CUDA 的opencv 必须编译 64 位得opencv,刚开始没有注意到这一点浪费了很多时间。所以在Windows环境下,如果要编译同时支持OpenGL和CUDA的opencv就必须下载QT源码编译安装64位的QT环境,再按照以下路径选择设置即可完成安装。
1 | Set QT_MAKE_EXECUTABLE to D:\Qt\5.9\mingw53_32\bin\qmake.exe |
1.2 解码
使用cv::cudacodec::createVideoReader(fname) 进行硬解码,解码后的数据直接存储在GPU中进行处理。但实际上这个语句的兼容性极差,前面提到opencv的硬编解码直接在NVIDIA 官方的编解码包Video Codec SDK 上实现的,这块基本属于opencv的边缘部分,很少人使用,官方针对这部分的更新也很缓慢,每当 Video Codec SDK 有了更新就很可能导致各种 Segmentation fault 。比如在使用cv::cudacodec::createVideoReader(fname)解码数据前,必须调用以下 Video Codec SDK 的函数进行初始化
1 | void* hHandleDriver = 0; |
而opencv没有对此进行任何封装,且比较依赖当前的CUDA版本,在 CUDA8.0 时支持较好(网上调查论坛结果,没有实践,实验室电脑CUDA版本为9.0)。
使用opencv封装之后的解码函数硬解码有各种意外发生,但使用NVIDIA 官方提供的编解码例程直接调用 Video Codec SDK 能正常完成编解码。可以排除底层环境导致的原因,相关问题在 opencv 的GitHub库中的issue中也有较多的讨论。
1.3 编码
硬解码部分的支持不是很完善,硬编码部分代码更不完善,目前只支持windows平台,且不支持HEVC的编码。
1.4 总结
目前为止在opencv中能够实现的有以下部分:
- H264,H265的cpu解码
- 复制解码后的数据到GPU,在GPU完成拼接工作
- H264的软编码
CUDA9.0中默认的Video Codec SDK版本使用dynlink_nvcuvid.h代替了nvcuvid.h 导致 opencv中的硬解码出现段错误,目前试验了很多方法还没有解决问题,应该可以通过单独更新 Video Codec SDK到最新的 8.1 版本解决,但为了不影响计算机中的整体环境还没有实际操作。H264,H265的硬解码理论上也是可以实现的(没有实际)。
1.5 参考资料
- How to setup Qt and openCV on Windows
- Problem in executing cv::cudacodec
- cv::cudacodec::createVideoReader segfault
- ‘Segmentation fault’ with gpu video decoding
- cv::cudacodec::VideoReader Class Reference
- GPU-Accelerated Computer Vision (cuda module)
2 ffmpeg中的数据结构
学习一个框架从他的数据结构入手可以很清晰地了解框架的操作对象,更好地把握数据处理过程,ffmpeg使用 C 语言构建,其中的数据结构均由结构体描述,目前为止已经有超过两千种的数据结构,下面是ffmpeg编解码常用的各种结构体,涉及到网络协议,封装格式,解码器信息,视频数据等重要的存储结构。
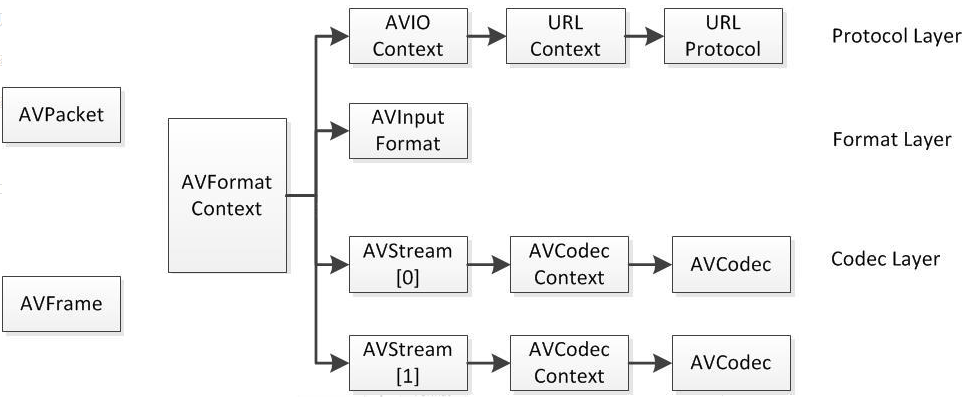
2.1 AVFormatContext
AVFormatContext可以说是贯穿ffmpeg始终的结构体,也是包含信息最多的一个结构体。包含了输入数据缓存,视音频流,视音频流个数,文件名,视频时长,比特率,元数据等重要信息。下面介绍的很多结构均是此结构体中的子结构。
2.2 AVIOContext
AVIOContext包含于AVFormatContext中,看名字便可知道主要和文件输入输出有关。主要包含了缓存开始的位置,缓存大小,当前指针读取位置,缓存结束位置,使用的网络协议等。
2.3 编解码器信息
AVCodecContext是其中复杂度很高的结构体,其中包含了很多编解码的具体属性,如编解码器的类型(视频或音频),具体的编解码器,平均码率,帧率,采样格式等等。
AVCodec包含于AVCodecContext中,存储着具体使用的编解码器信息。
2.4 AVPacket
AVPacket主要存储了解码前的一帧数据,相对来说比较简单,除此之外还存储了数据的大小,时间戳等信息。
2.5 AVFrame
AVFrame主要存储了解码后的一帧数据以及该帧数据的相关信息,类如是否为关键帧,原始数据类型,视频的宽,高等。
2.6 相关结构的关系
下图来自雷霄骅雷神的博客,清晰地表示以上结构体之间的依赖关系