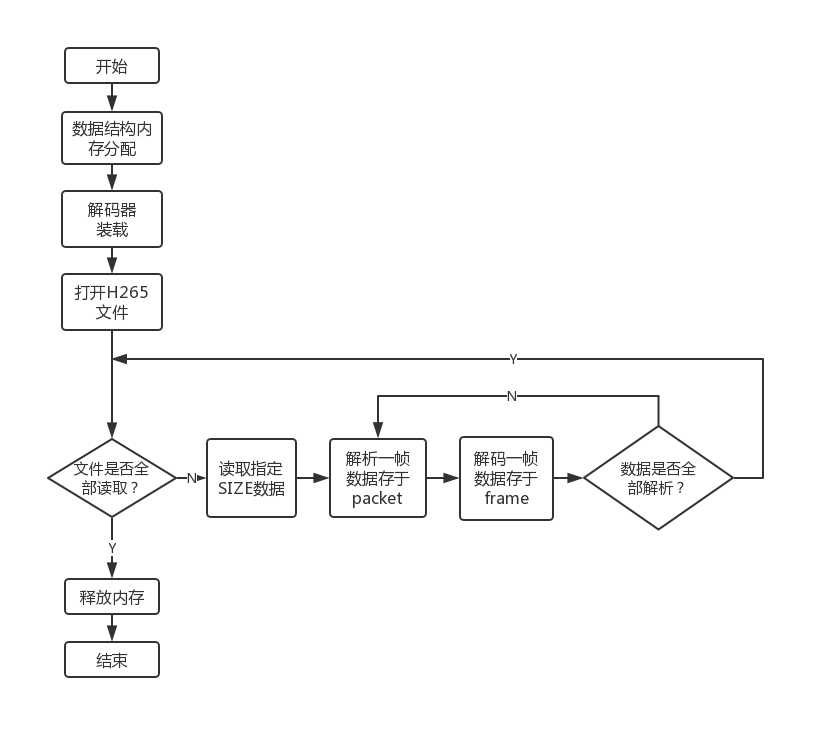
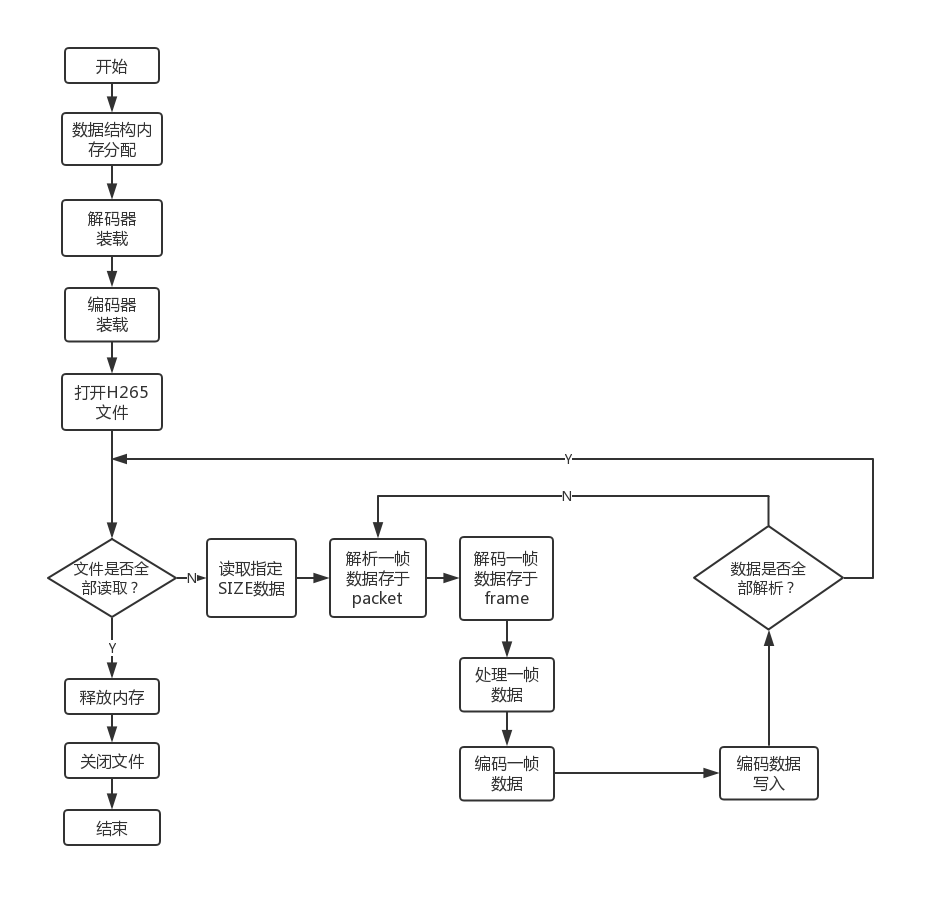
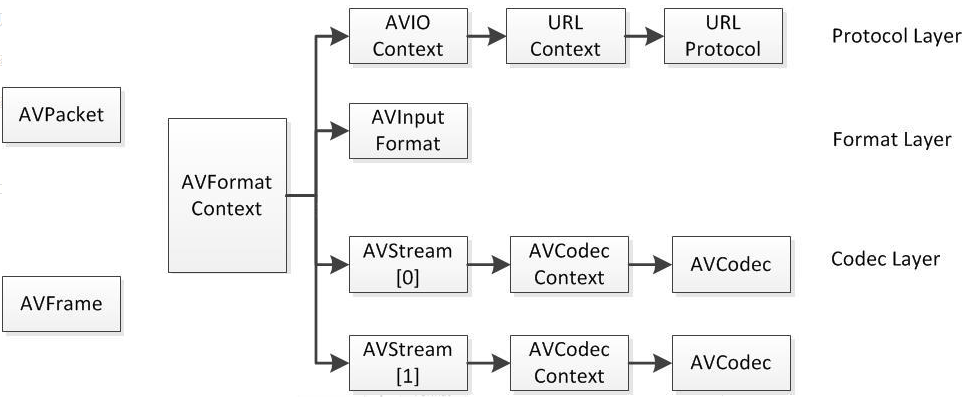
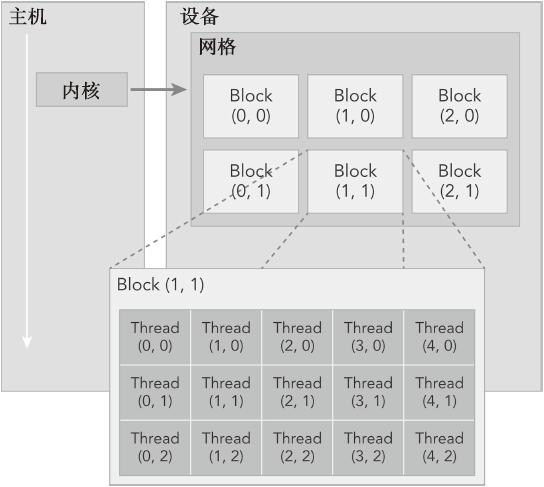
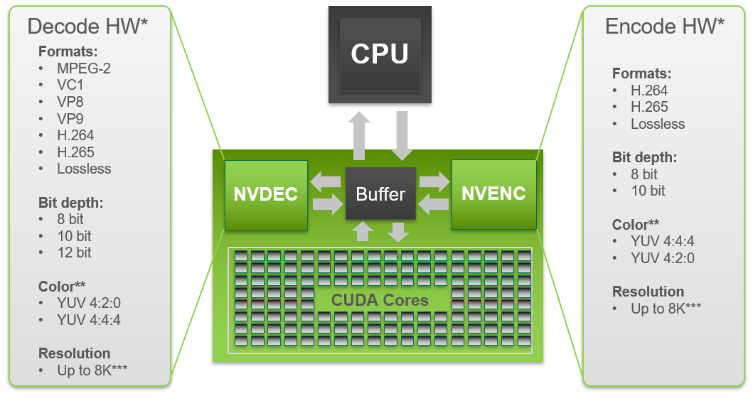
本周解决了之前编码丢帧的问题。将原来测试中的单路解码根据项目需求改为双路解码,但由于ffmpeg的解码方式,可能造成两路解码帧的不同步,便会造成后续拼接部分的错位。总体来说大的主框架已经完成,但还有很多细节的部分需要调试。目前拼接使用的上下分割的拼接方式,隔行拼接计算量更大,且 UV 数据的处理还未找到解决方法。
除此之外阅读了 Geoffrey Hinton 关于模型简化的论文 Distilling the knowledge in a neural network ,论文中使用复杂模型来训练简单模型,使简单模型具有复杂模型的性能,从而达到简化模型结构的目的。
1 视频编解码
上次实验之所以有丢帧的现象是因为没有没有清洗(flush the decoder/encoder) 编解码器。在解码的时候,将所有编码数据全部送到解码器之后,在结束前需要调用avcodec_send_packet(dec_ctx, NULL)往解码器输入 NULL 将解码器中剩余的帧”冲洗”出来,编码同理。
1.1 双路解码一路编码
前面说到,ffmpeg使用以下四个函数进行编解码:
avcodec_send_frameavcodec_receive_packetavcodec_send_packetavcodec_receive_frame
但是这几个函数的使用并不是很有规律地进行。比如avcodec_send_packet与avcodec_receive_frame配合使用完成解码功能。调试发现,两个函数并非严格地交替执行,执行情况根据具体的编码视频不同而不相同。所以在双路解码时不能仅仅通过对以上两个解码函数使用上的同步而达到对解码后帧的同步。实际操作中,通过对两路解码状态的监测实现双路解码的同步。
1.2 编解码工作计划
基本完成了deepwater.exe inputA inputB output形式的可执行程序的主要内容,内部调用NVIDIA的编解码器进行编解码操作。根据之前的测试结果,奇偶分割或者上下分割两种方式,在未加去隔行处理的情况下表现差异不大,且均达到肉眼不可分的清晰度。但是YUV420P格式在奇偶分割的处理中存在着 UV 分量不可分的情况。
除了以上提到的内容,对项目进一步的工作安排还不是太清楚。
2 提炼模型
提高模型性能的一个简单方法便是训练多个不同的模型,然后使用多个模型识别的平均值作为最总结果,但是这样会导致预测模型过于笨重,且耗费过多的计算资源。本篇文章通过特殊的训练方法从笨重的模型中提炼信息到简单模型中,从而简化模型。
2.1 实现方法
本篇文章中提到的训练方法其实比较简单。例如,当我们训练分类模型时使用的标签均为硬标签(hard targets),即所属类别处为1,其余为0。但我们实际训练模型的输出为该输入所属类别的概率(softmax)。
$$
q_i = \frac{exp(z_i/T)}{\sum_jexp(z_j/T)}
$$
而我们的标签(hard targets) 中却并没有体现出该图片像其它类别的概率,也就是说我们的硬标签中包含的信息不如softmax多。于是作者使用训练之后复杂模型的输出来作为图片的标签(soft targets) 来训练简单的模型。最后得出的结果表明,虽然大大简化了模型的结构,却可以得到接近复杂模型的正确率,如下图所示。

除此之外作者还针对不同的模型给出了多种训练方法,可通过调整上式子中的温度指数$T$ 来调节概率的分布情况。且使用不同的目标函数,不同的代价函数也均能使用这种方法来简化模型。使用软标签(soft targets)训练使得训练的速度更快,仅使用原训练数据 3% 的训练量即可达到
接近原模型的测试正确率,具体指标如下图所示。

2.2 总结
以上方法的核心便是通过对训练集标签的改进,将 hard targets 改进为 soft targets。使得标签能够提供更多的信息,从而可以达到简化模型的目的,在实际部署中非常有用。
2.3 参考文献
- Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. “Distilling the knowledge in a neural network.” arXiv preprint arXiv:1503.02531 (2015). pdf (Godfather’s Work)